近年、Deep learningと呼ばれる手法を用いることで、音声から文字へ変換する音声認識の精度が向上しています。Deep learning は、大量の学習データを利用することで、精度が向上することが知られています。Google や Amazon の音声認識システムは、クラウド上で大量のデータから学習しており、実用で利用できる精度になっています。身近なところでは、YouTube の字幕があります。YouTube の字幕は、Google の音声認識技術を利用しているため、高い精度の認識結果であり、動画における発言時間も取得することができます。
例えば、小樽市の議会は、以前から、YouTubeによる動画配信をしており、小樽市議会のYouTube字幕を取得することができます(2020年7月1日の時点では、字幕ありの動画数が433でした)。ここでは、2020年(令和2年)6月30日のYouTube配信の文字起こしを見てみます。
私たちは、文字起こしデータから、WordCloudを作成し、YouTubeへ結びつけるしくみを作りました。下記に作成したWordCloudを貼り付けます。

2020年6月30日の本会議1のYouTubeの字幕(文字起こし)をWordCloudへ変換
使い方は下記の通りです。
- WordCloudの単語(例えば、新型コロナウイルス)をクリックする。
- クリックした単語の発言時間と発言内容が表示される。
- 時間をクリックすると、指定した時間からYouTubeの動画が始まる。
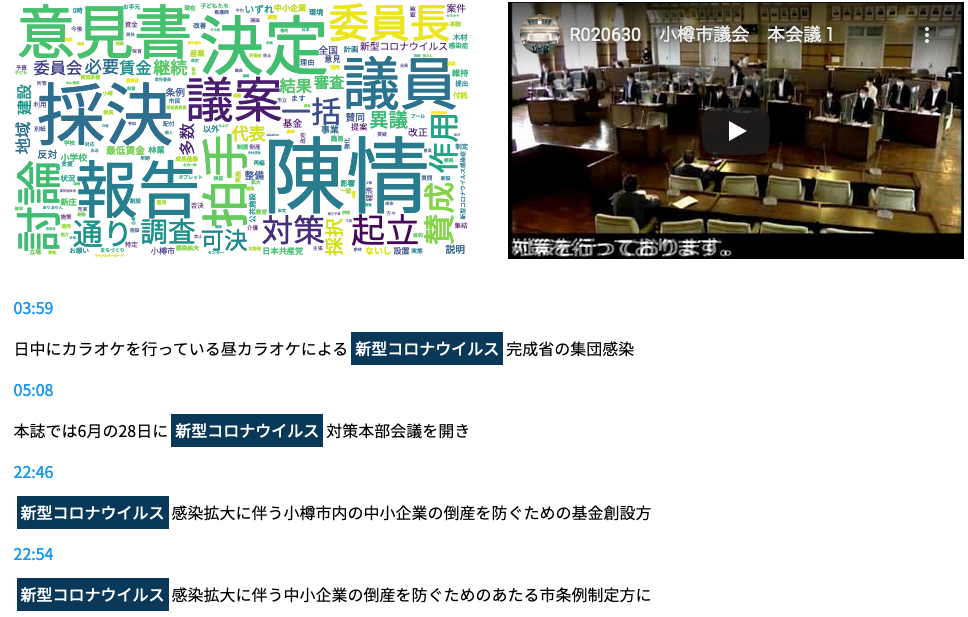
字幕は、100%の音声認識結果とは限らないため、正確性に問題があります(誤りが含まれていることがあります)。そこで、私たちは、一次情報となるYouTubeの動画へ結びつけることで、ユーザが正確な情報を確認できるようにしました。
YouTubeの字幕(書き起こし)からWordCloudを作成する方法について説明します。まず、YouTubeの各動画の字幕(書き起こし)を1つずつファイルに保存します。次に、ファイルに含まれる音声認識結果を単語に分割して、出現頻度を数えて、WordCloudを生成します。最後に、WordCloudからYouTubeの動画を見るためのhtmlを作成します。この作成については、桧森さんと笠原さんと森谷さんが担当してくれました。WordCloud作成のポイントは、単語選択と単語分割の方法を決めること(担当:桧森さん)、WordCloudの単語をクリックしたら単語を含む発言を再生させること(担当:笠原さん)、ウェブサイトの見た目を良くすること(担当:森谷さん)でした。